The Transformer model is a revolutionary deep learning architecture used for natural language processing (NLP) and other AI tasks. Introduced in 2017 by Vaswani et al., Transformers have replaced RNNs and LSTMs in many applications due to their efficiency and ability to process entire sequences at once.
🔍 Key Concepts of Transformers
- 🧠 Self-Attention Mechanism – Helps the model focus on relevant parts of the input.
- ⚡ Parallel Processing – Unlike RNNs, Transformers process all words simultaneously.
- 🔀 Positional Encoding – Adds order to input sequences.
- 📊 Multi-Head Attention – Improves the model’s ability to capture relationships between words.
🛠️ Transformer Architecture
The Transformer consists of an Encoder-Decoder structure:
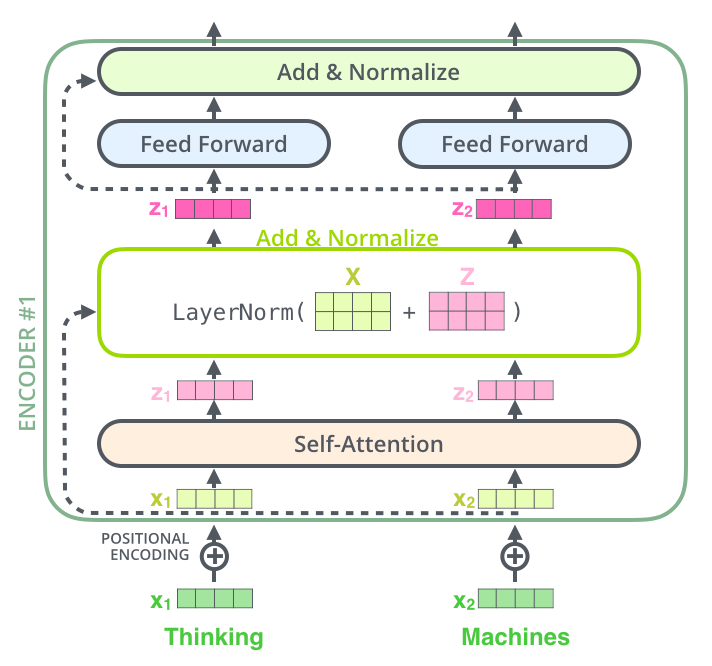
The encoder processes the input sequence, while the decoder generates output step by step. The main component of each layer is self-attention and feed-forward networks.
🔄 How Self-Attention Works?
Self-attention is the heart of the Transformer model. It allows the model to pay attention to different words in a sentence when making predictions.
Each word in the input gets transformed into Query (Q), Key (K), and Value (V) vectors. Then, attention scores are computed to determine which words are most important for understanding the current word.
✅ Advantages of Transformers
- 🚀 Faster than RNNs due to parallel processing.
- 📝 More accurate in handling long text sequences.
- 🌐 Widely used in ChatGPT, BERT, and other AI models.
Comments
Post a Comment
Thanks for visiting! I love reading your comments.